Research
All
2026
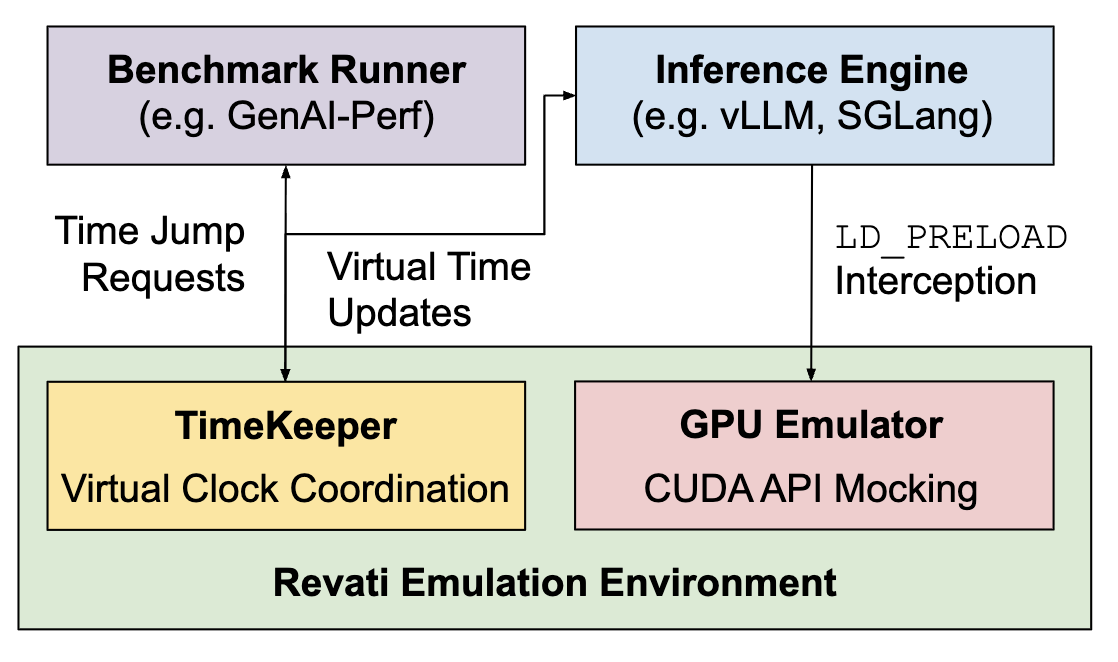
Revati: Transparent GPU-Free Time-Warp Emulation for LLM Serving
arXiv
·
05 Jan 2026
·
arxiv:2601.00397
2025
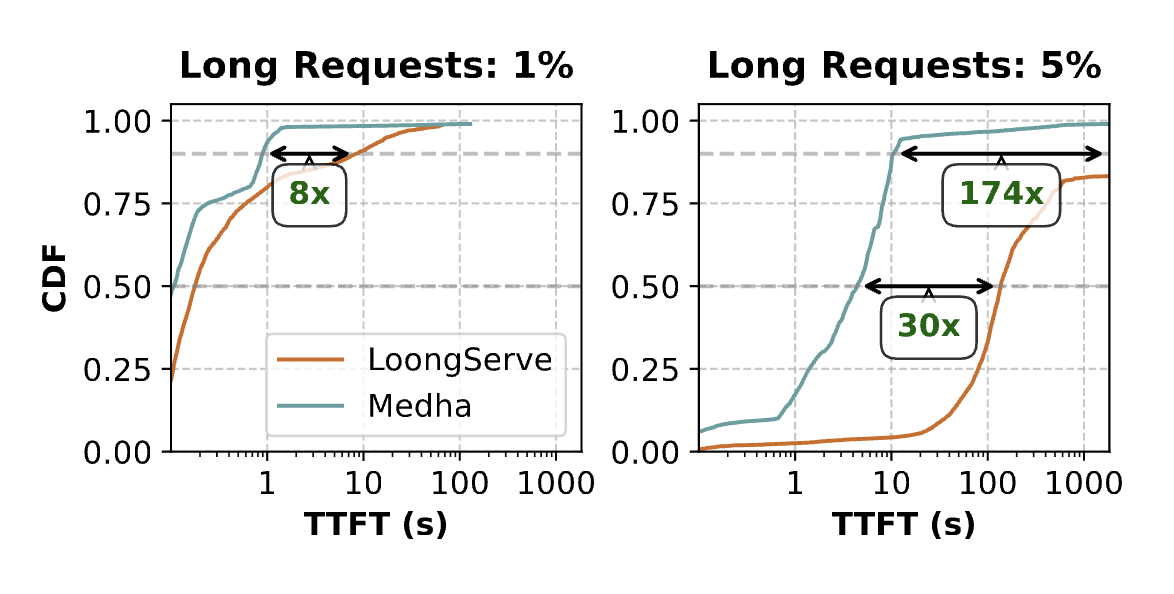
No Request Left Behind: Tackling Heterogeneity in Long-Context LLM Inference with Medha
arXiv
·
27 Nov 2025
·
arxiv:2409.17264
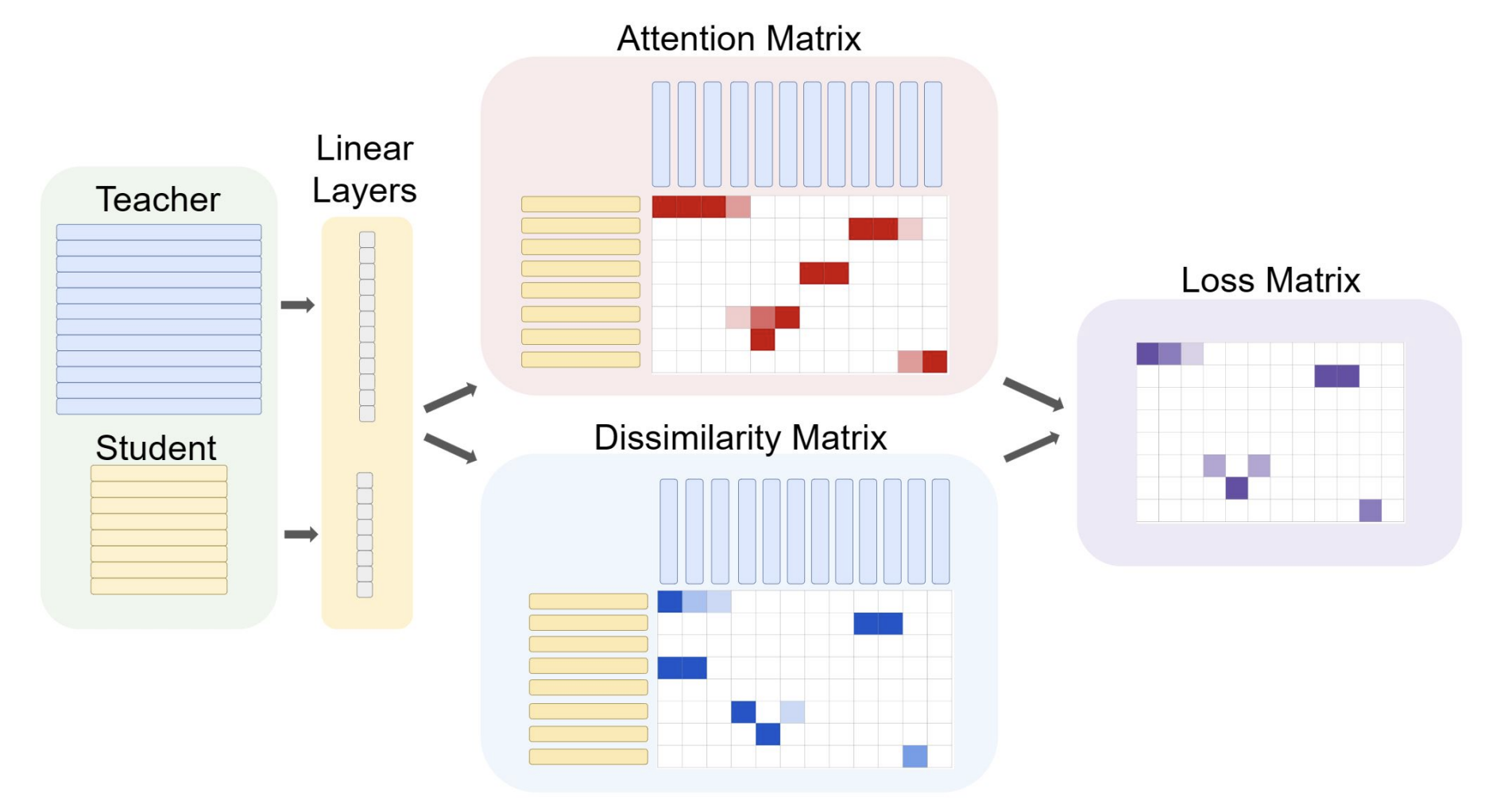
STRIDE: Structure and Embedding Distillation with Attention for Graph Neural Networks
arXiv
·
19 Aug 2025
·
arxiv:2310.15938
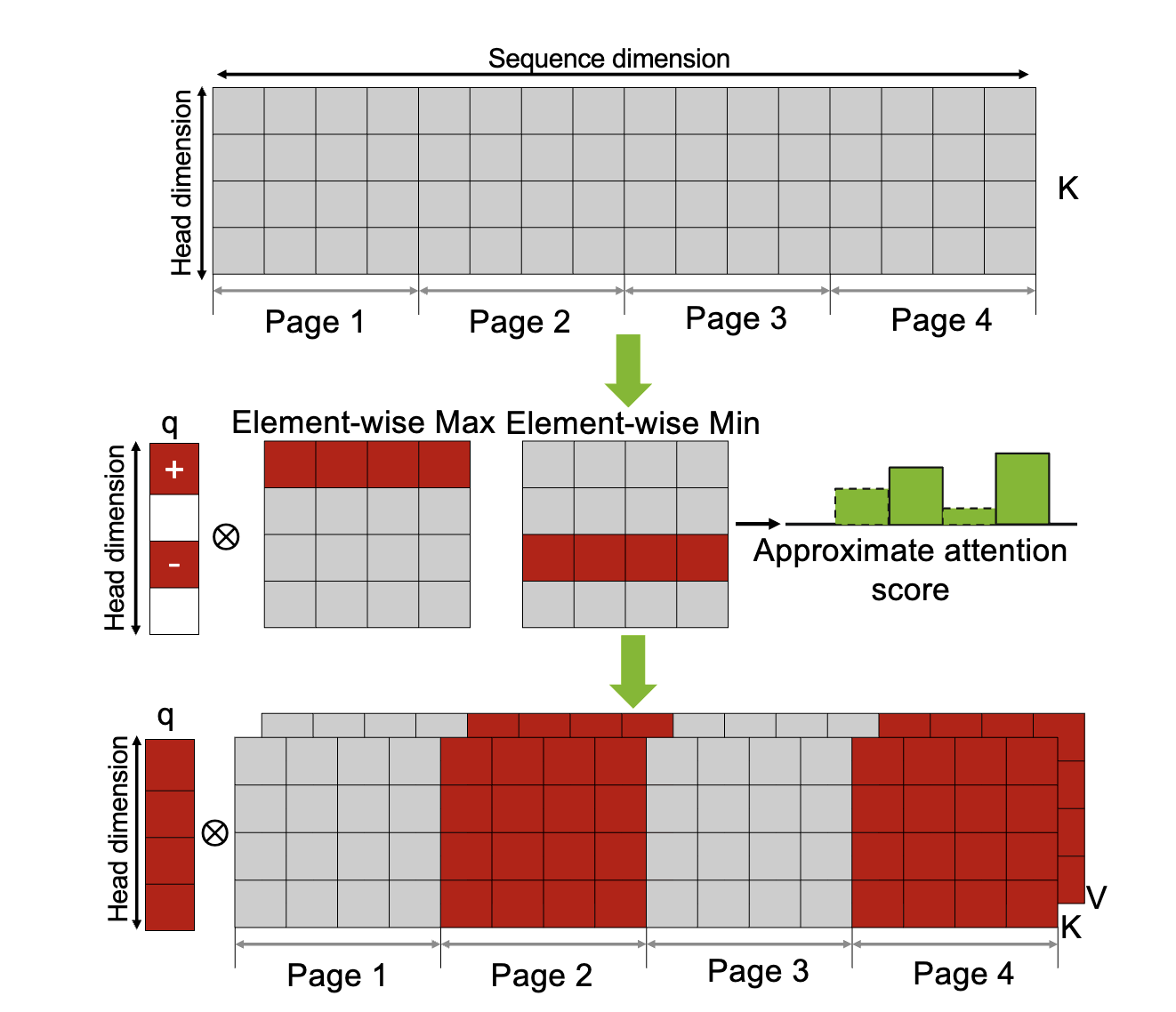
RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV Cache Compression
21st European Conference on Computer Systems, 2026, Edinburgh
·
14 Aug 2025
·
arxiv:2502.14051
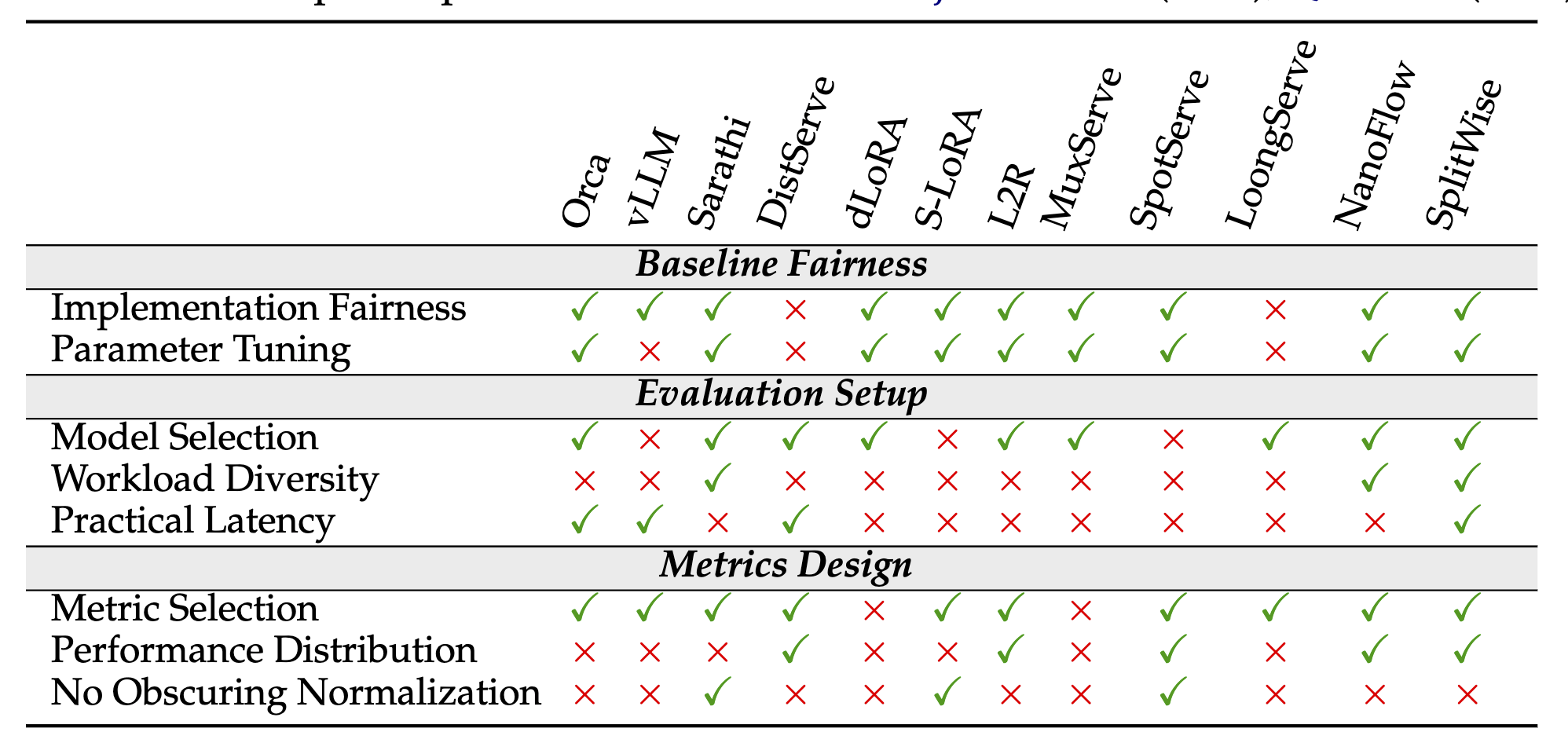
On Evaluating Performance of LLM Inference Serving Systems
arXiv
·
15 Jul 2025
·
arxiv:2507.09019
Toward Weight Sharing Paradigm for Efficient AI: Training and Inference Serving
ACM SIGOPS Operating Systems Review, Volume 59, Issue 2
·
01 Jul 2025
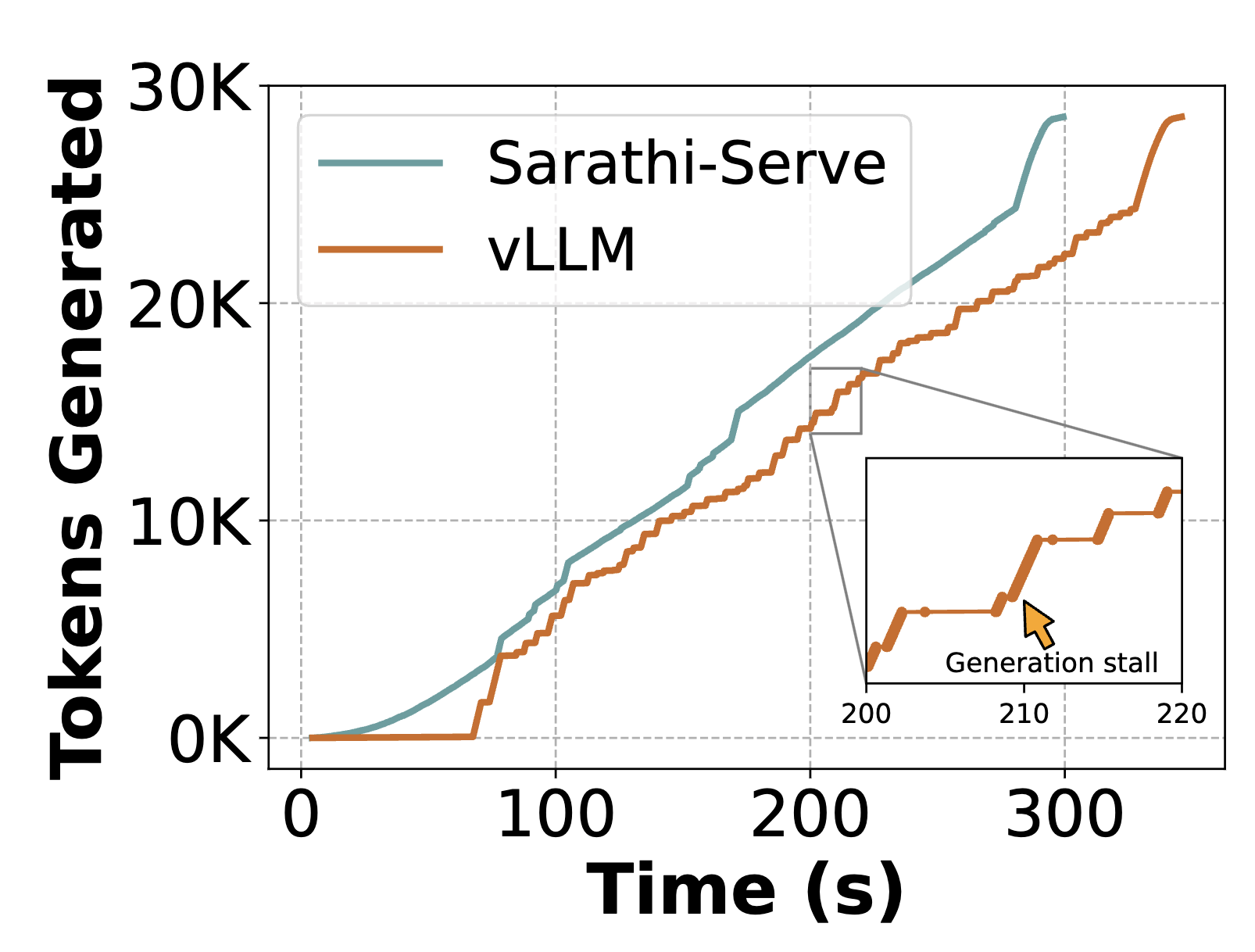
Efficient LLM Inference via Chunked Prefills
ACM SIGOPS Operating Systems Review, Volume 59, Issue 2
·
01 Jul 2025
EMPIRIC: Exploring Missing Pieces in KV Cache Compression for Reducing Computation, Storage, and Latency in Long-Context LLM Inference
ACM SIGOPS Operating Systems Review, Volume 59, Issue 2
·
01 Jul 2025
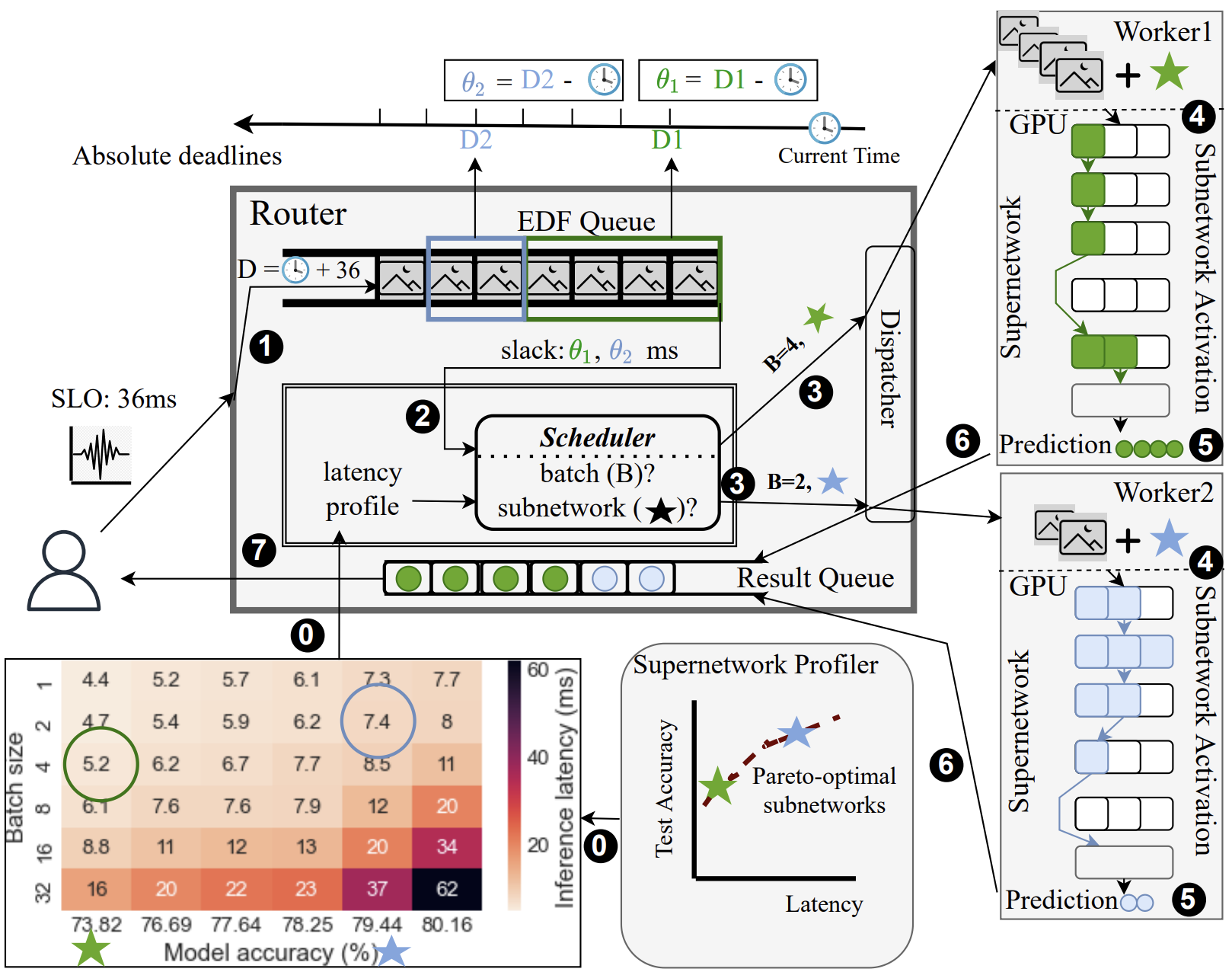
SuperServe: Fine-Grained Inference Serving for Unpredictable Workloads
22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 2025)
·
28 Apr 2025
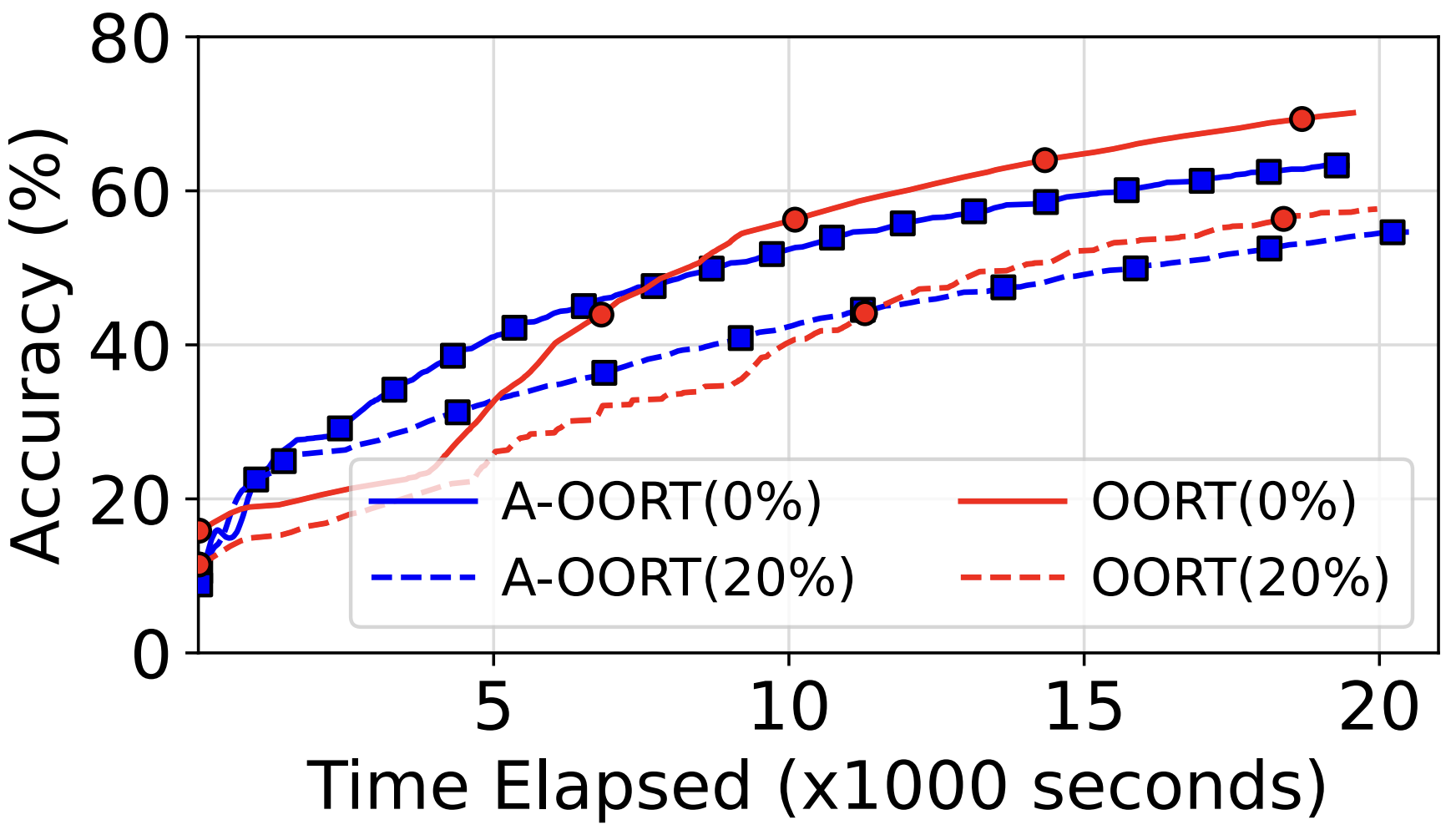
Client Availability in Federated Learning: It Matters!
5th Workshop on Machine Learning and Systems (EuroMLSys), co-located with EuroSys '25
·
30 Mar 2025
·
doi:10.1145/3721146.3721964
2024
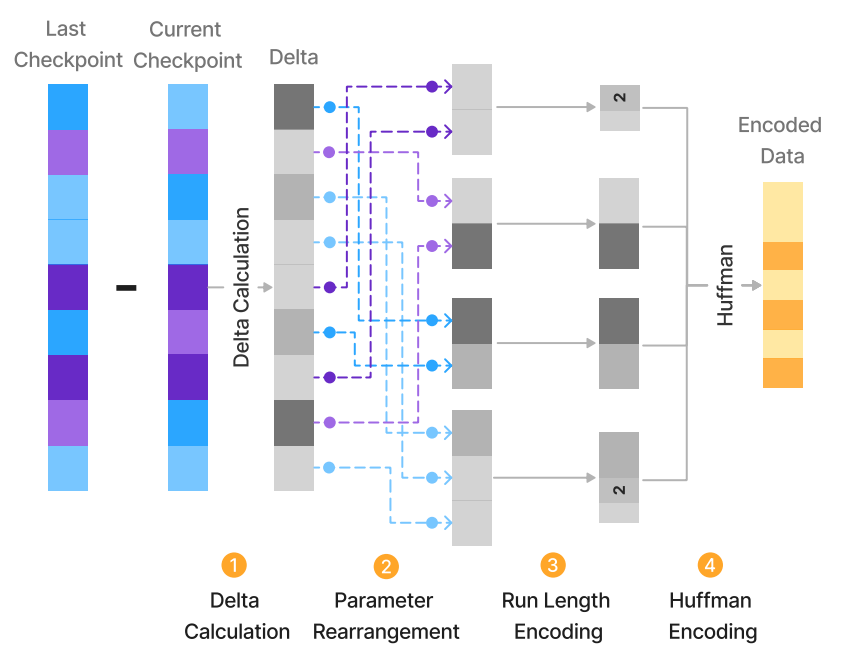
Inshrinkerator: Compressing Deep Learning Training Checkpoints via Dynamic Quantization
15th ACM Symposium on Cloud Computing (SoCC 2024), Redmond, USA, Nov 2024
·
15 Oct 2024
·
arxiv:2306.11800

Etalon: Holistic Performance Evaluation Framework for LLM Inference Systems
arXiv
·
02 Sep 2024
·
arxiv:2407.07000
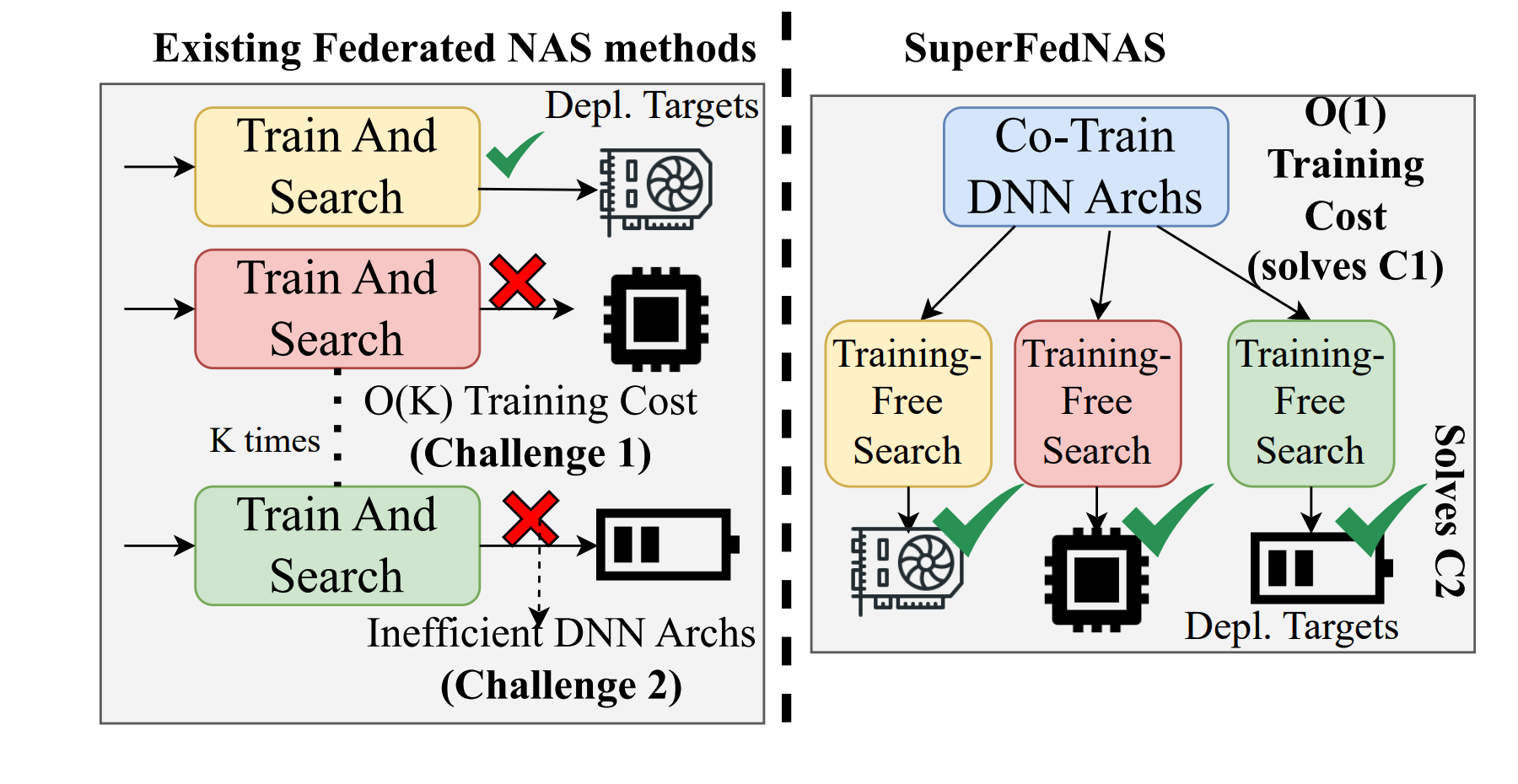
SuperFedNAS: Cost-Efficient Federated Neural Architecture Search for On-Device Inference
18th European Conference on Computer Vision (ECCV 2024), Milano, Italy, Oct 2024
·
12 Jul 2024
·
arxiv:2301.10879
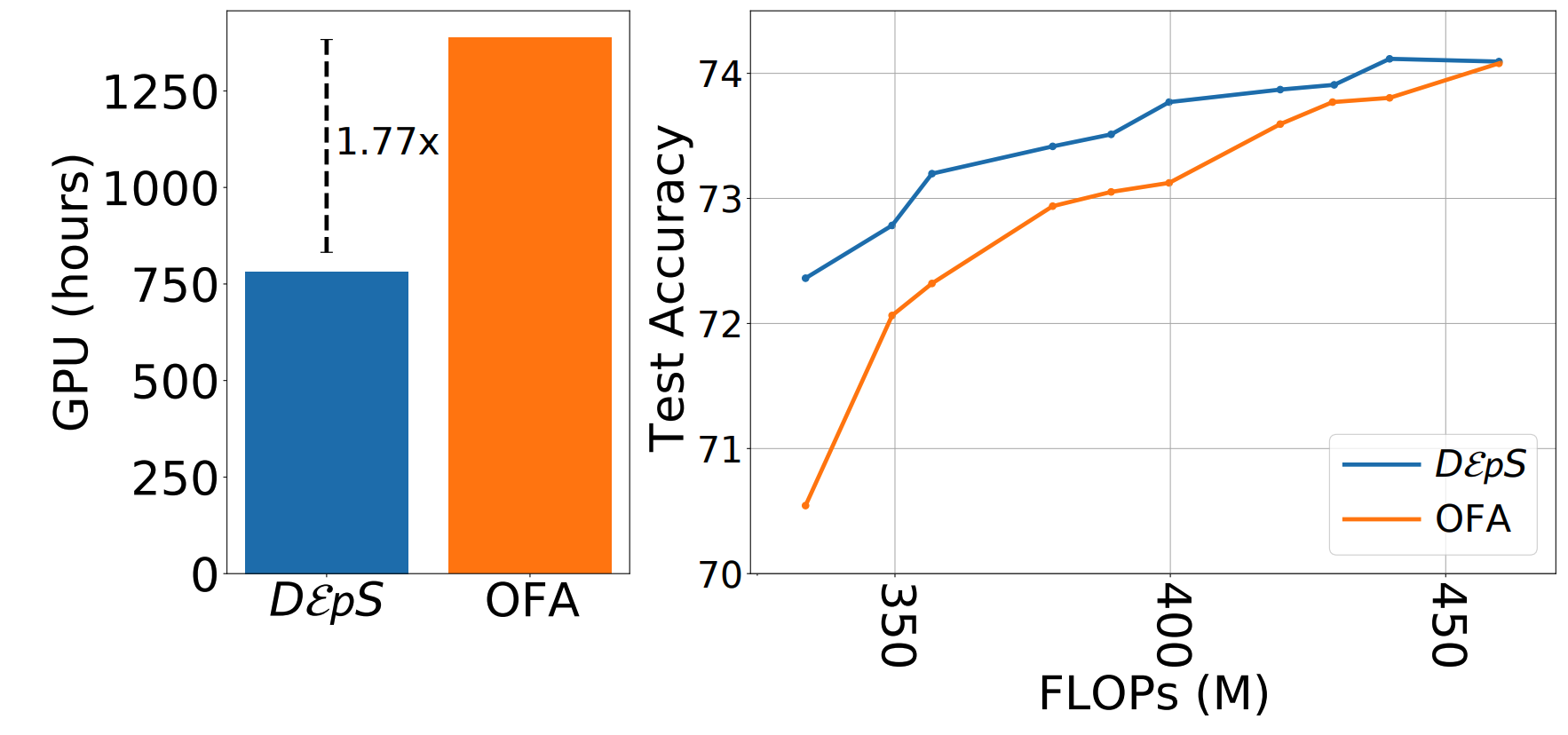
DεpS: Delayed ε-Shrinking for Faster Once-For-All Training
18th European Conference on Computer Vision (ECCV 2024), Milano, Italy, Oct 2024
·
09 Jul 2024
·
arxiv:2407.06167
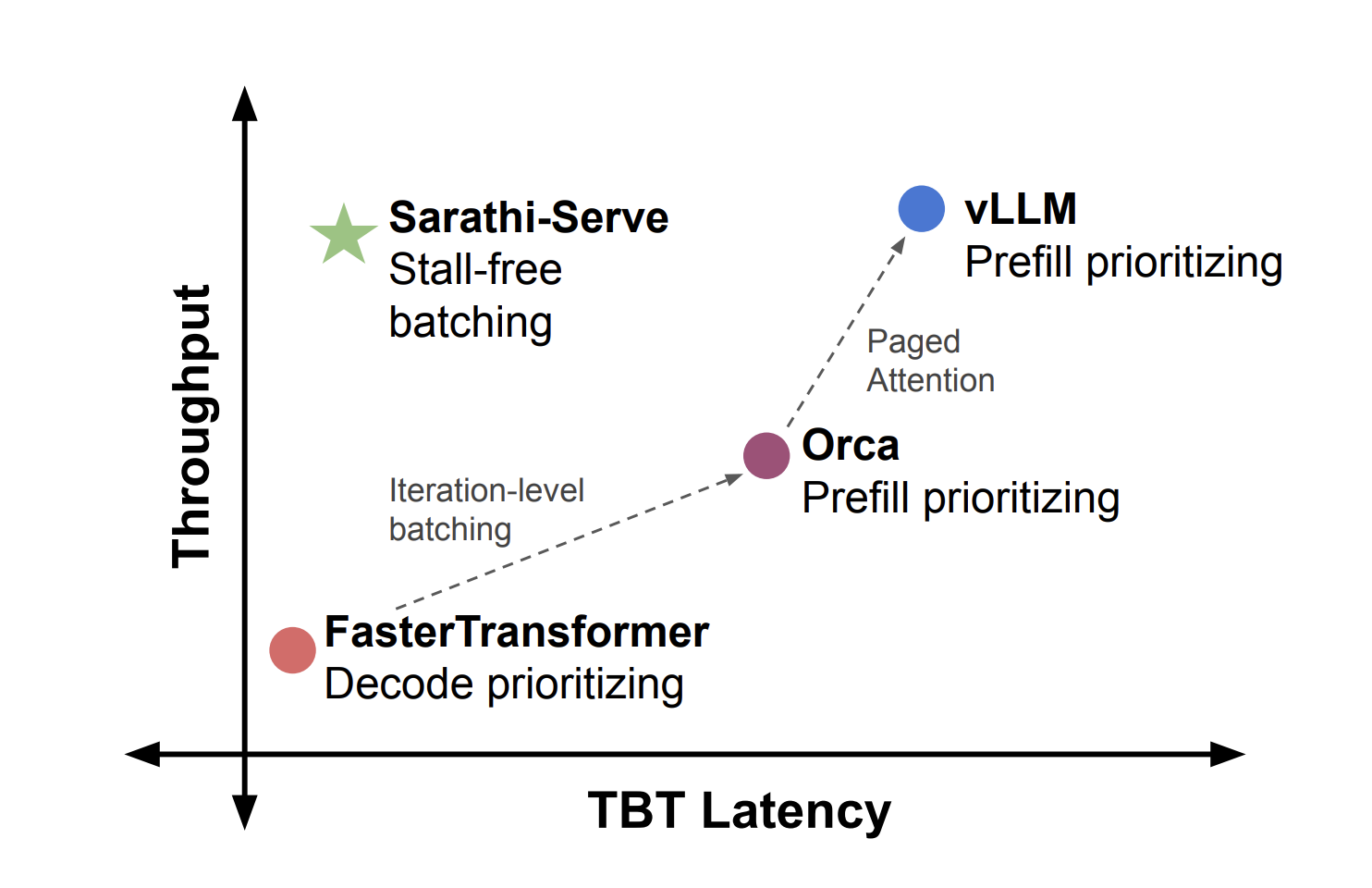
Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
18th USENIX Symposium on Operating Systems Design and Implementation (OSDI’24), Santa Clara
·
19 Jun 2024
·
arxiv:2403.02310
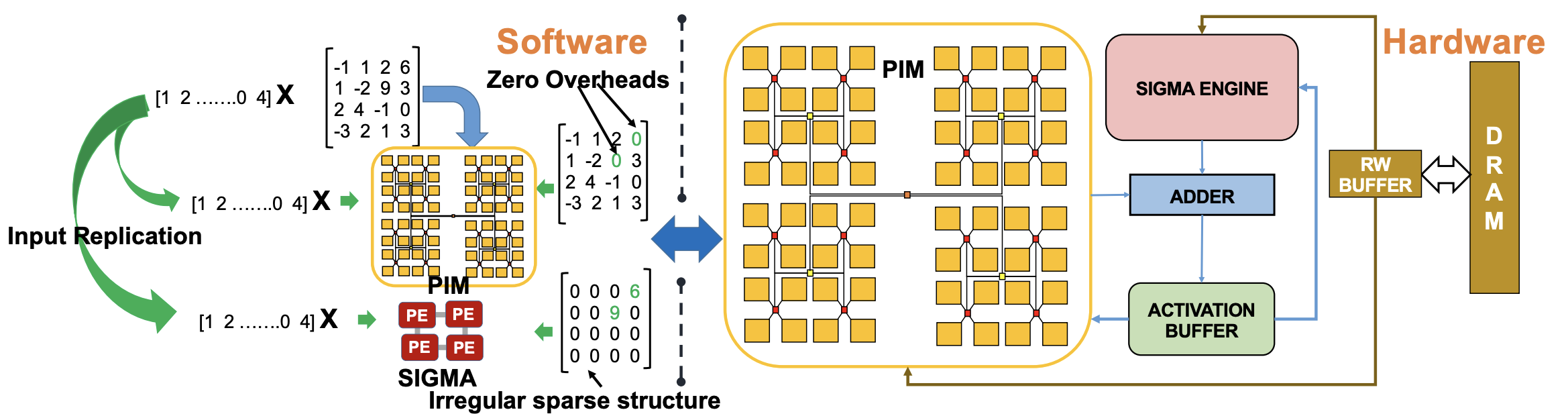
Harmonica: Hybrid Accelerator to Overcome Imperfections of Mixed-signal DNN Accelerators
Proc. 38'th IEEE International Parallel and Distributed Processing Symposium (IPDPS'24)
·
27 May 2024
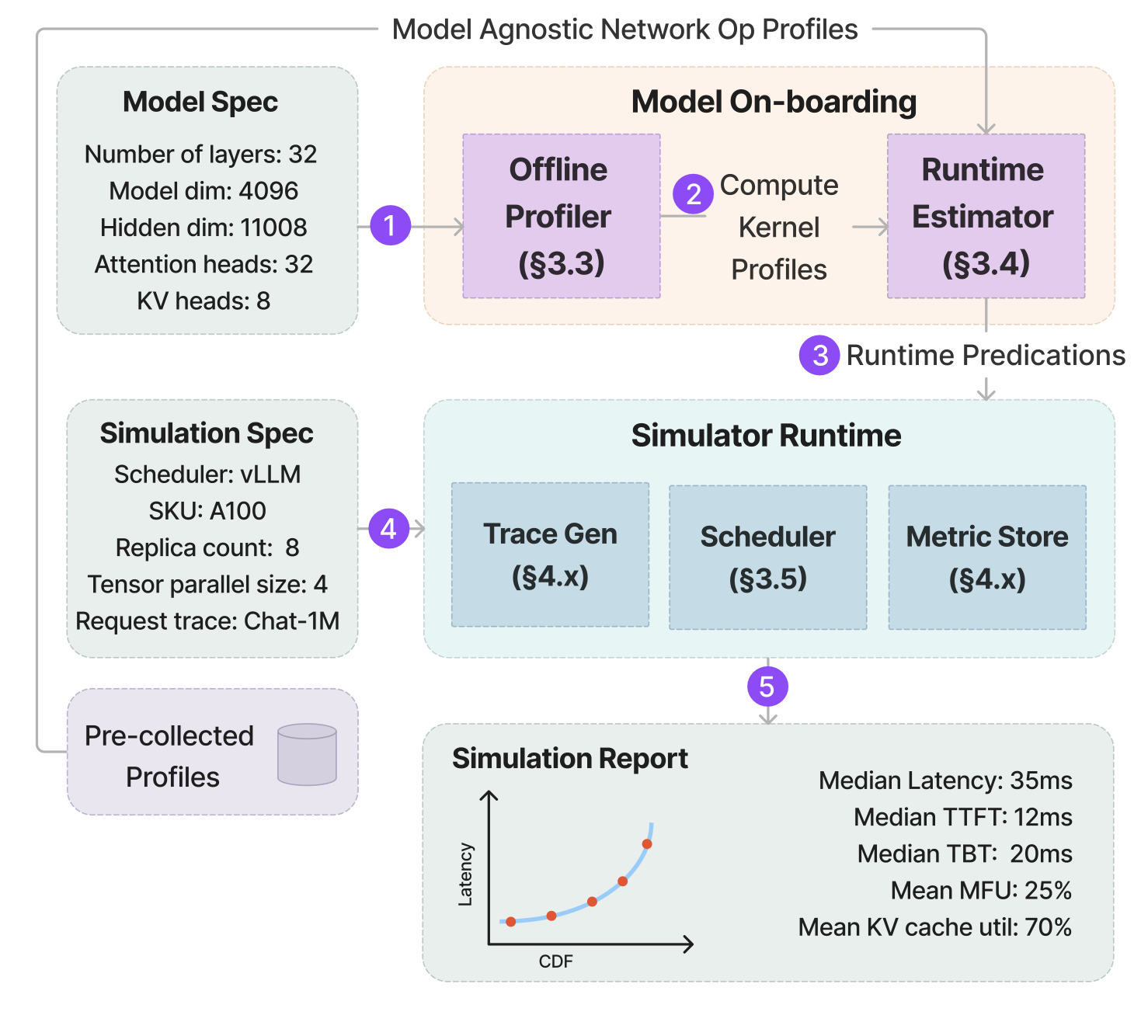
Vidur: A Large-Scale Simulation Framework For LLM Inference
7th Annual Conference on Machine Learning Systems (MLSys’24), Santa Clara
·
22 May 2024
·
arxiv:2405.05465
2023
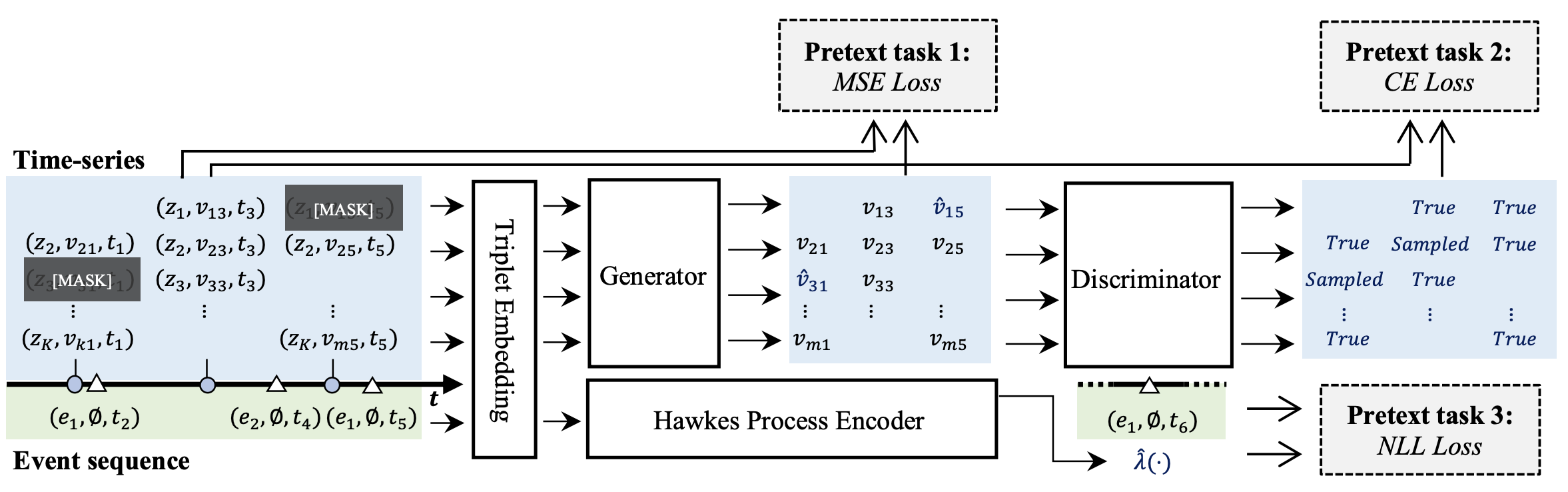
TransEHR: Self-Supervised Transformer for Clinical Time Series Data
Proc. of Machine Learning for Health (ML4H'23)
·
10 Dec 2023
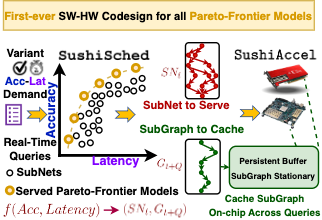
Hardware–Software Co-Design for Real-Time Latency–Accuracy Navigation in Tiny Machine Learning Applications
IEEE Micro
·
01 Nov 2023
·
doi:10.1109/MM.2023.3317243
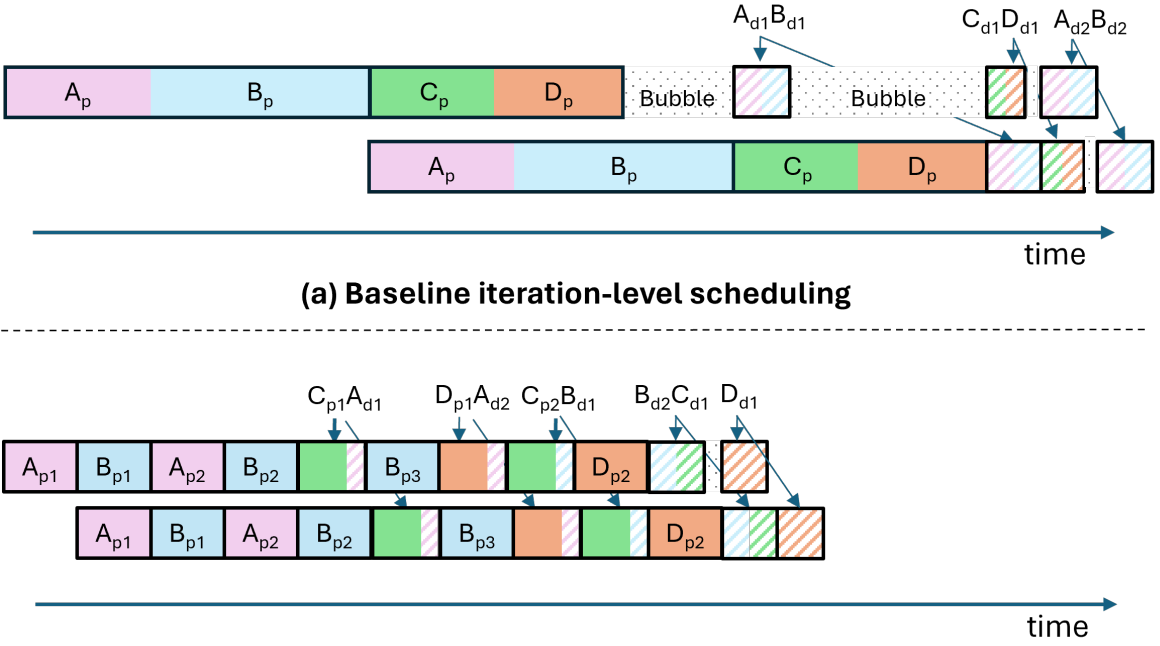
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
arXiv
·
01 Sep 2023
·
arxiv:2308.16369
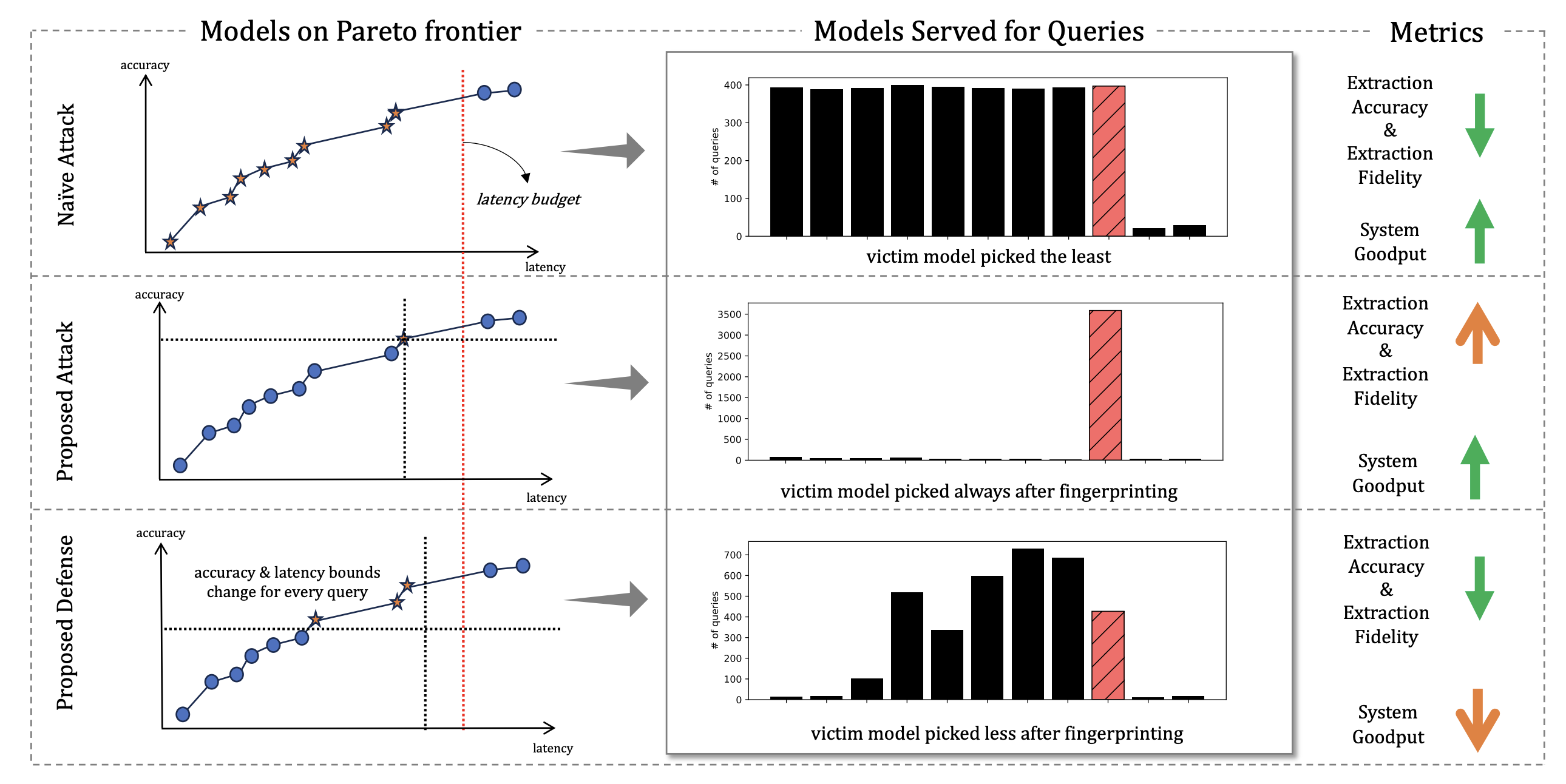
Pareto-Secure Machine Learning (PSML): Fingerprinting and Securing Inference Serving Systems
arXiv
·
08 Aug 2023
·
arxiv:2307.01292
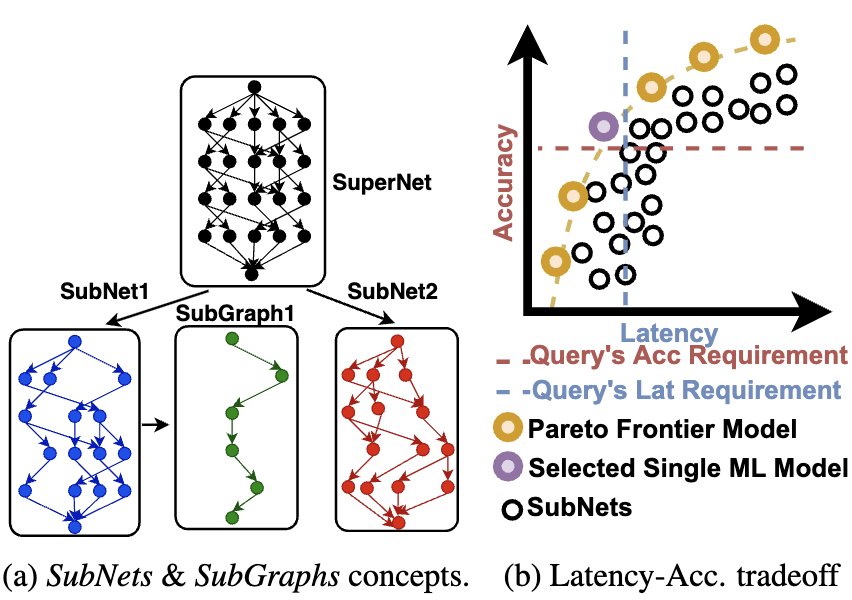
Subgraph Stationary Hardware-Software Inference Co-Design
Proc. of Sixth Conference on Machine Learning and Systems (MLSys'23)
·
03 Jul 2023
·
arxiv:2306.17266
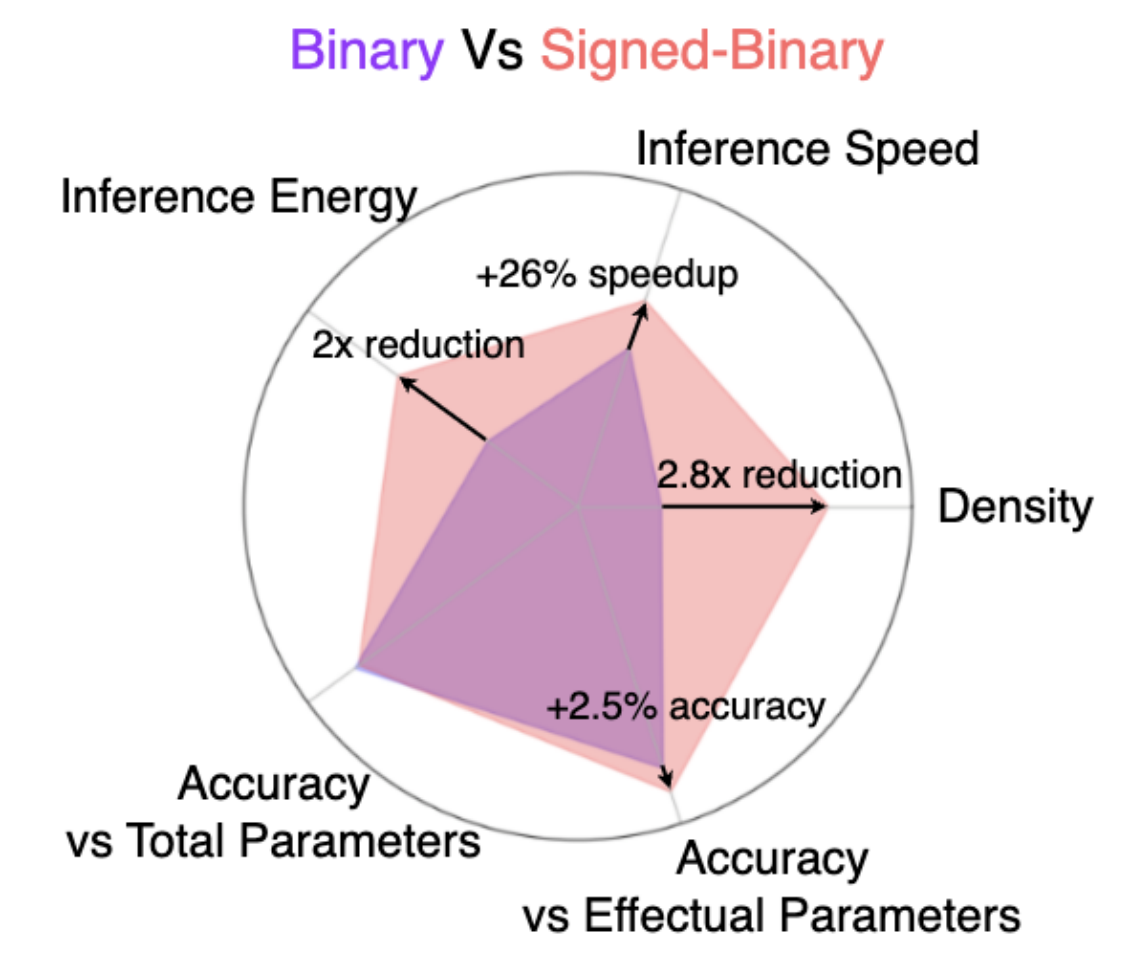
Signed-Binarization: Unlocking Efficiency Through Repetition-Sparsity Trade-Off
Proc. of 3rd On-Device Intelligence Workshop, Machine Learning and Systems (MLSys'23)
·
01 Jun 2023
2022
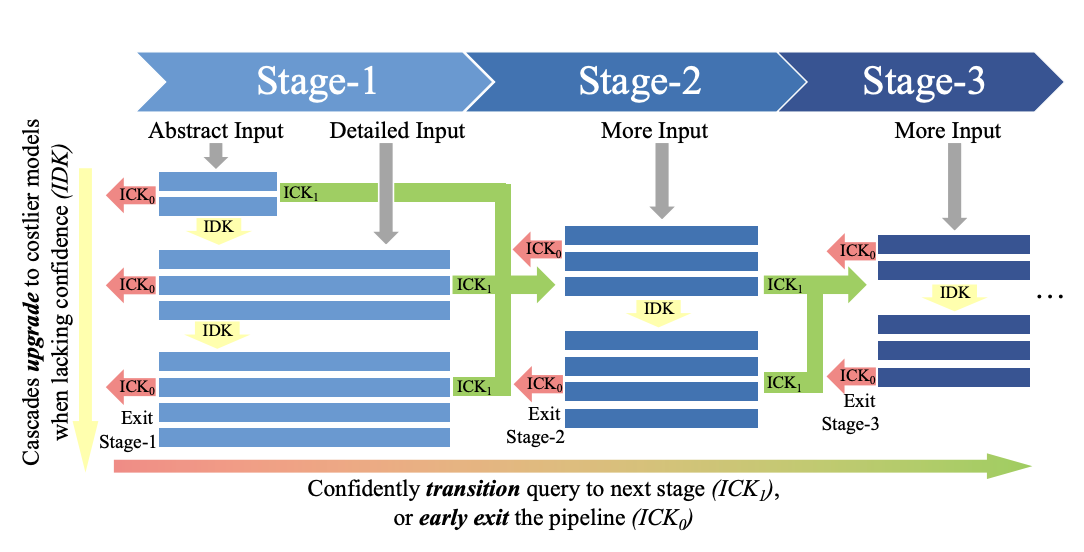
UnfoldML: Cost-Aware and Uncertainty-Based Dynamic 2D Prediction for Multi-Stage Classification
Proc. of 36'th Conference on Neural Information Processing Systems (NeurIPS'22)
·
31 Oct 2022
·
arxiv:2210.15056
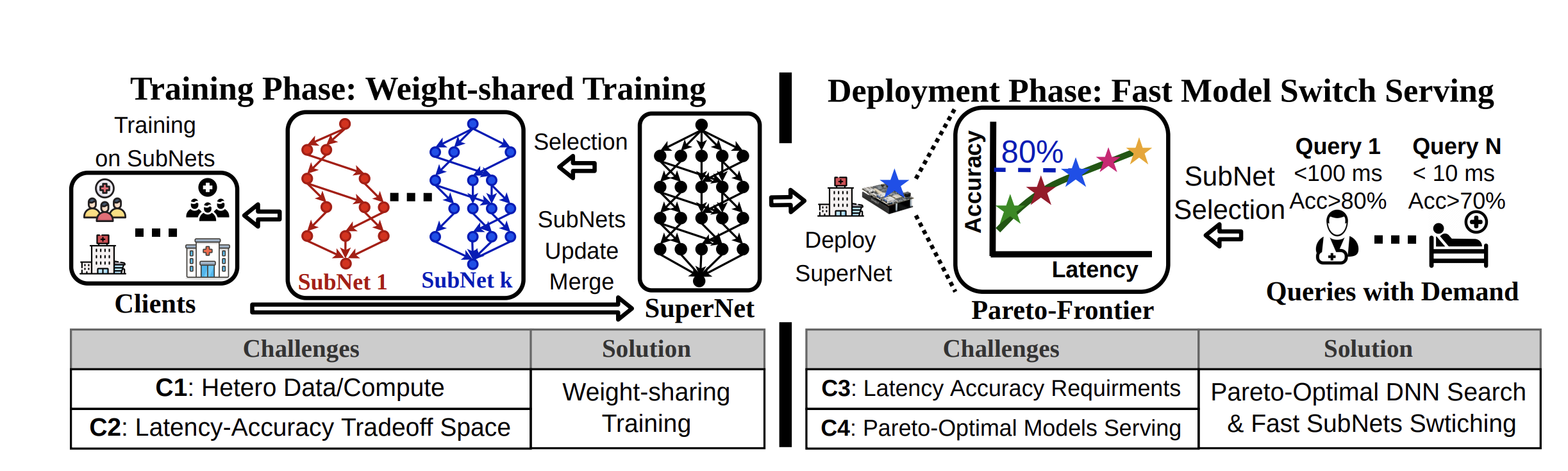
Enabling Real-time DNN Switching via Weight-Sharing
Proc. of 2nd Architecture, Compiler, and System Support for Multi-model DNN Workloads Workshop
·
01 Jun 2022
2021

CompOFA: Compound Once-For-All Networks for Faster Multi-Platform Deployment
Proc. of International Conference on Learning Representations (ICLR'21)
·
27 Apr 2021
·
arxiv:2104.12642
2020
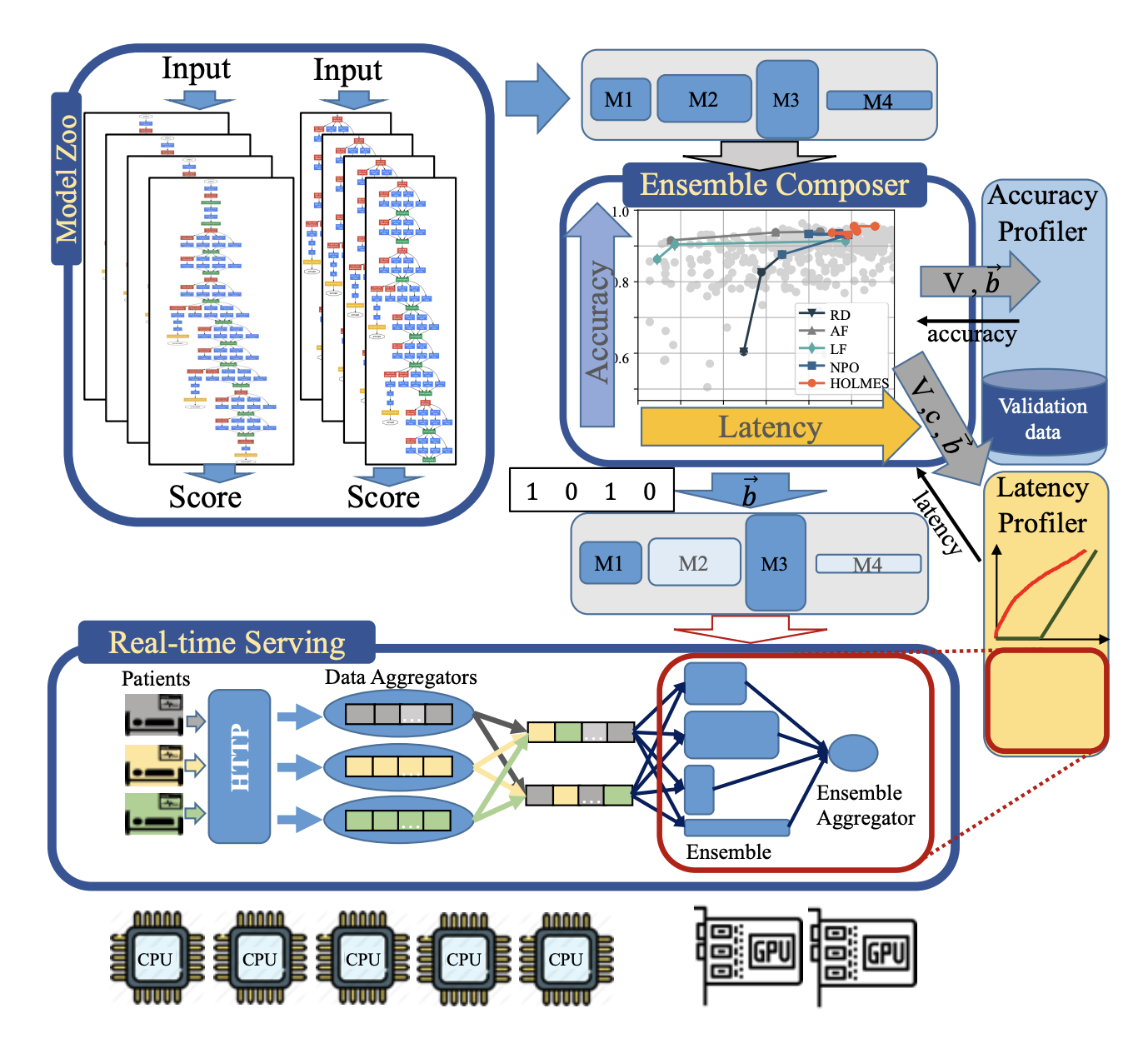
HOLMES: Health OnLine Model Ensemble Serving for Deep Learning Models in Intensive Care Units
Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining
·
20 Aug 2020
·
doi:10.1145/3394486.3403212